



澎峰科技一直在关注计算基础软件,都是希望通过库、框架、异构计算框架构建统一的开源库,降低应用的迁移成本。

近日,嘉程创业流水席第203席【探讨中外大模型在端侧落地的最新趋势】,邀请了澎峰科技创始人张先轶分享,主题是《异构计算软件栈与大模型推理应用》。
以下为正文部分:
非常荣幸有机会来介绍一下我们异构计算软件栈和大语言模型的推理优化方面的工作。

澎峰科技是一家做算力的公司,我们并不是研究AI算法和AI模型,而是负责底层的Infra层的工作,包括我们的算子库、异构计算框架等等。目前我们面向的主要应用领域中,人工智能是非常重要的一个,涉及AI的推理,以及一些训练的加速等等。另外一个比较重要的领域是传统的科学工程计算,比如像EDA、华大九天等,都是我们的客户。还有信号处理的应用,因为澎峰科技的专长就是构建算力的软件基座,来支持上端的应用算力,无论是人工智能、科学工程计算还是信号处理,都能更好地利用底层的异构计算硬件,这是我们长期在做的事情。
以“计算视角”的算力分级
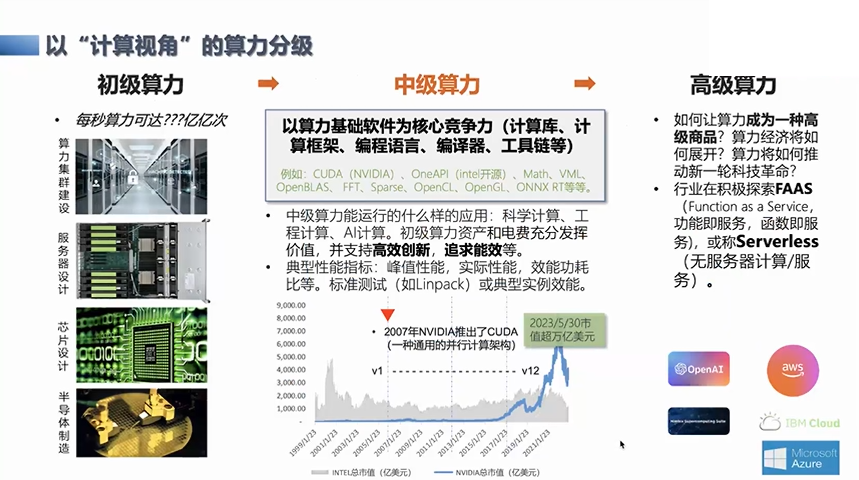
从整个算力的角度来说,我认为算力可以分为初级、中级和高级算力。比如典型的像英伟达,它有自己的CUDA生态,有自己的GPU,或者是Intel公司相关的事情(OneAPI),它其实已经达到了中级算力的状态,它以硬件和算力基础软件为互相的竞争壁垒。在这个基础上,他们也在面向应用领域做各种垂直系统。这里最典型的就是英伟达,无论是面向人工智能的垂直云系统,还是在生物信息学等领域,都有相应的解决方案,这是目前国际市场中整体算力市场的发展状况。而国内的一些初创芯片公司,大部分还是停留在PK硬件峰值性能,而这部分的算力基础软件跟国际主流还有一个比较明显的差距。
算力基础软件领域
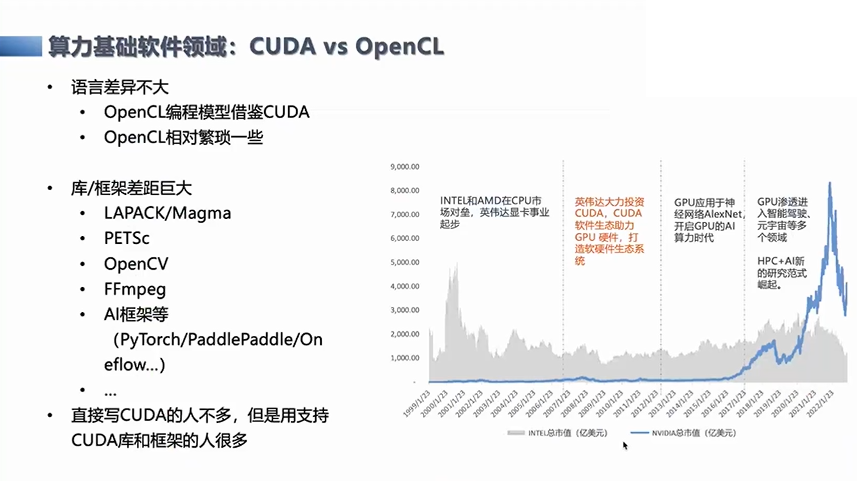
比如典型的像英伟达的CUDA的这部分生态,经过了十几年的发展,优于其他的开源的标准,不管是OpenCL或者其他家推出的,基本上现在提到异构计算,不管是在服务器上的训练,或者是边缘端,这些场景下的CUDA用得比较广泛,CUDA也几乎都是胜利者。这里我们观察到它的主要优势,为什么它能获得胜利?一个就是在库和框架上获得了比较多的生态价值。
开源数学计算库面临分散的问题
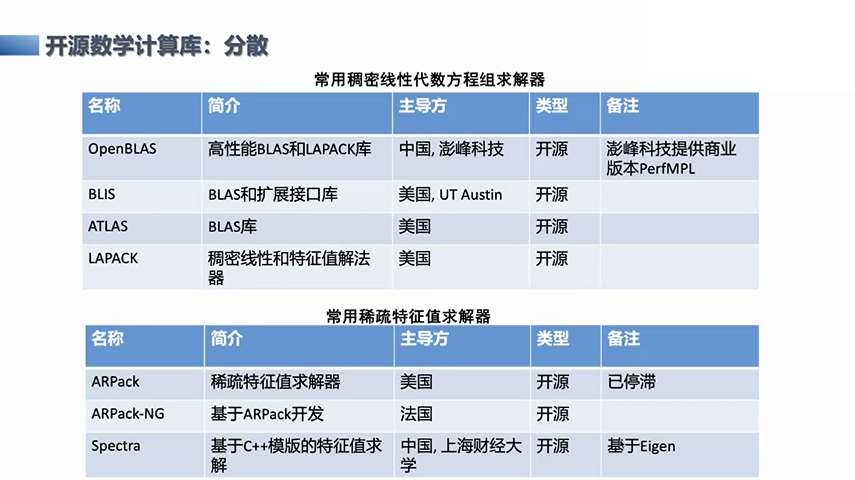
相应的,这一方面,如果不用芯片公司提供的闭源产品,而是想利用一些开源或基于开源的软件来做基础层的工作,目前这些计算领域可能会遇到一个比较大的问题,就是分散。比如开源的很多基础计算的软件库,无论是做AI中的DNN的library,还是科学工程计算里的矩阵计算,或者是面向信号处理的快速傅里叶变换,基本上每一个开源都是分散的、相对割裂的状态,实际上这非常不利于系统层的工作或研究。推进工作也比较困难,因为你想提供一个统一的版本,对于用户来说就要处理各个点上的问题。
开源矩阵计算库OpenBLAS
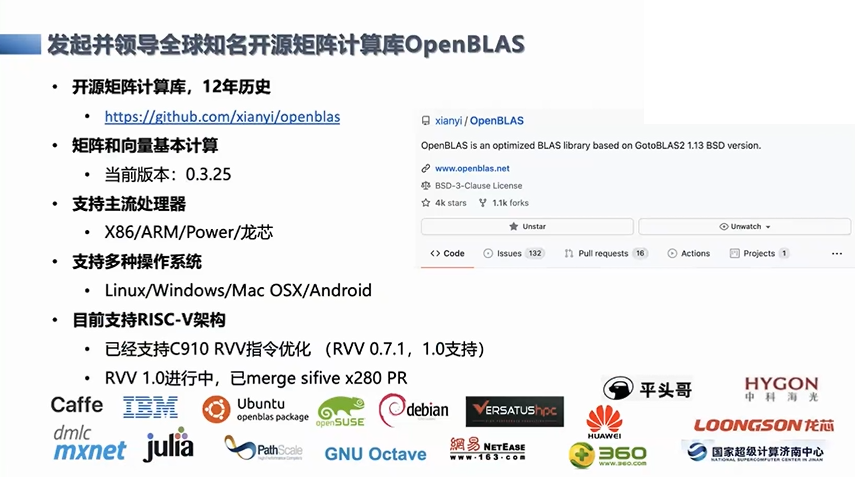
稠密矩阵计算的OpenBLAS,这是我们长期领导和维护,有十二年的历史,是国际上排名前三的开源矩阵计算库。这跟我们后面提到的现在做的大语言模型密切相关,因为现在的大语言模型其实很多的计算瓶颈都在矩阵计算上,这也是我们多年积累的一些技术的路径。
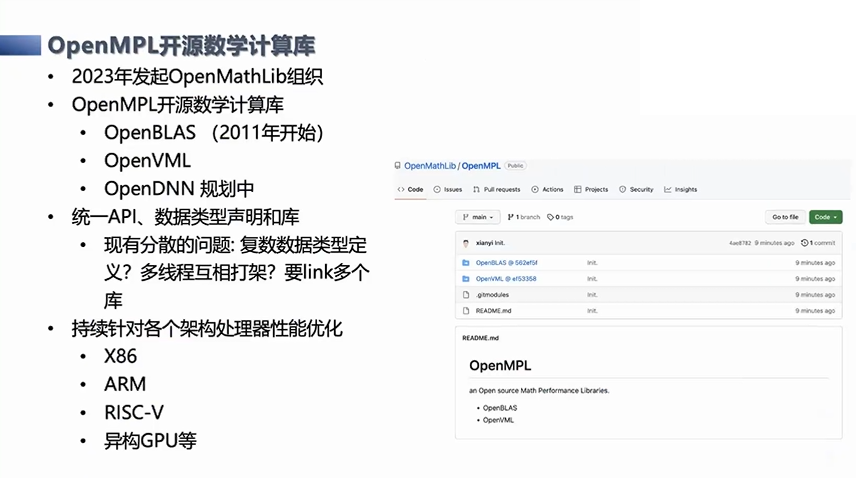
在我们成功的OpenBLAS开源项目基础上,我们想做更多的事情,来解决在Infra层的问题。所以我们在今年发起了OpenMathLib组织,希望拓展一个伞状的基础项目,去提供统一的API接口,解决它的很多问题,这样可以让计算层的应用更方便地利用到底层的算力,也可以避免算力应用被某一家芯片公司所绑定。当然我们也是刚刚开始,后面还有很多要做的。除了这种纯CPU的版本,我们也会对异构的GPU版本做相应的工作。
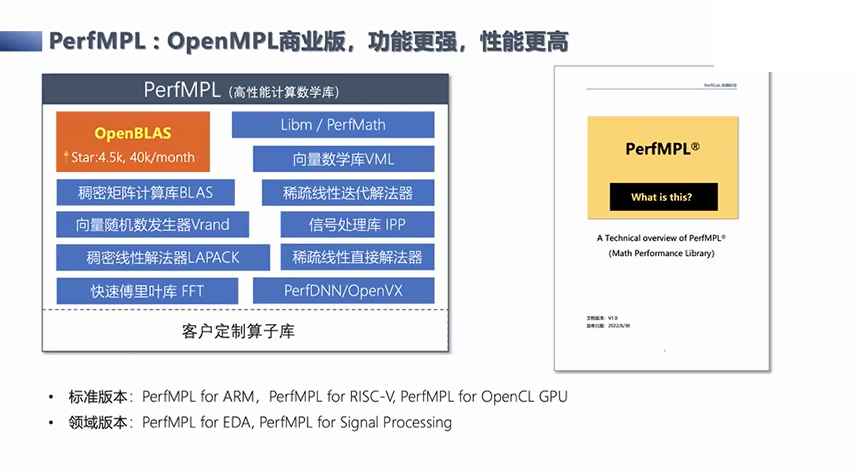
在开源项目的基础上,另外我们也在构建相应的商业版本,它的性能更强,功能更多。而且这个版本已经在国内的很多应用场景中得到了使用,比如从智算到科学工程计算等等。
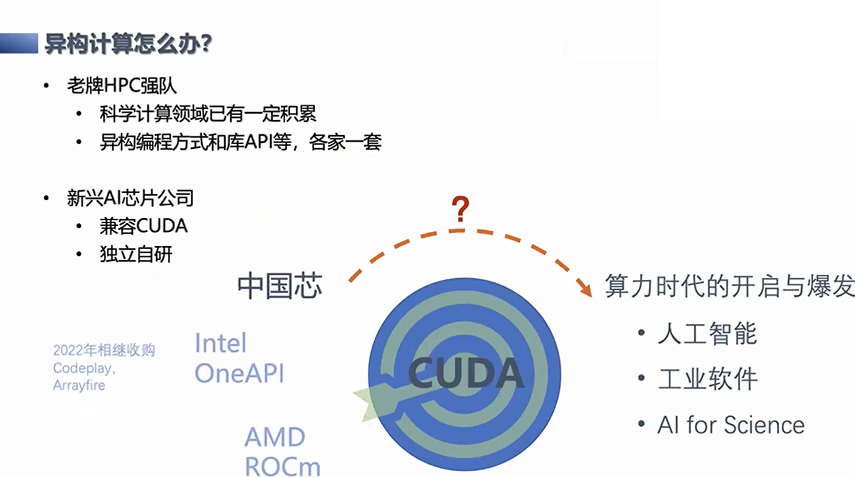
除了解决单独一个算子或者算子库层面的问题,我们还要再往上走一步,就是面向异构框架的问题,因为CUDA不仅有库,还有语言,它已经成了一个异构的代名词。对于其他的设备来说,是不是要完全依靠CUDA来做?还是另外有其他选择,这也是我们目前在思考的一个问题。
PerfXAPI异构计算框架
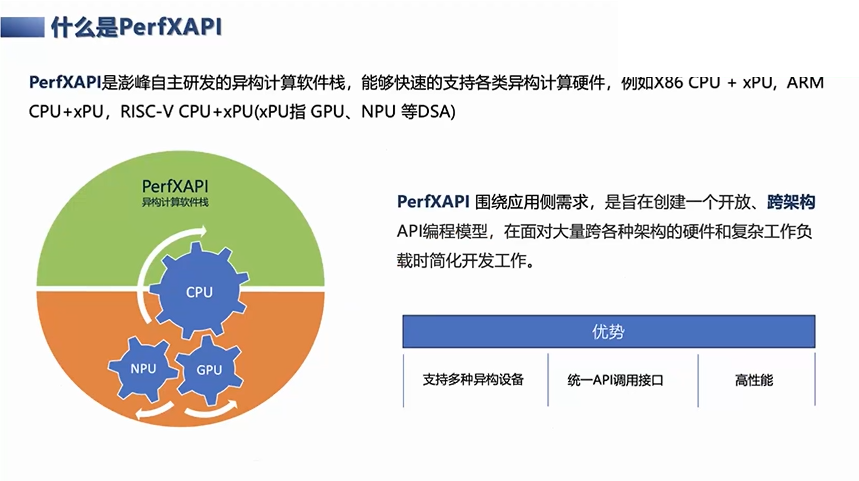
目前我们给出的答案就是在应用接口或者是API的一侧,构建了一个围绕着应用侧需求的异构API的编程模型。我们主要有几点优势,一个是支持了多种异构的计算设备。二是有统一的API接口的调用,应用可以在多种的异构平台上做无缝地迁移。最后是我们也满足了高性能。
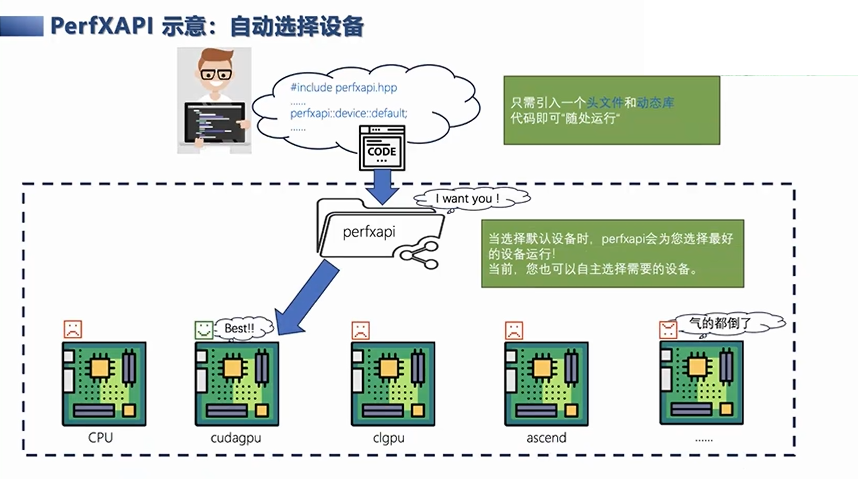
举一个简单的例子,比如用户可能有多种异构设备,无论是服务器端的CPU+GPU和NPU,还是现在拓展到边缘服务器或边缘计算节点的情况下,这里的计算调用或使用,都可以用一套代码来解决,它可以自动选择和切换设备。当你切换到不同的设备上的时候,它会检查当前的配置,把相应的计算任务调度到适合的计算节点上。
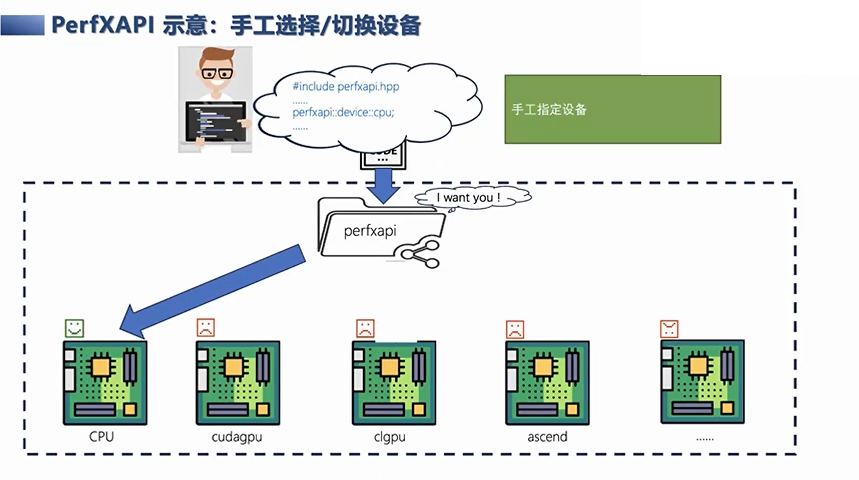
除此之外,我们也可以让用户手动指定或切换,比如把相应的计算任务指定到OpenCL的GPU上,这样就会直接用OpenCL GPU。当切换到另外一台没有OpenCL GPU的设备上,就会自动回到CPU端运行你的算子或框架等等,这是我们整体上做的PerfXAPI。
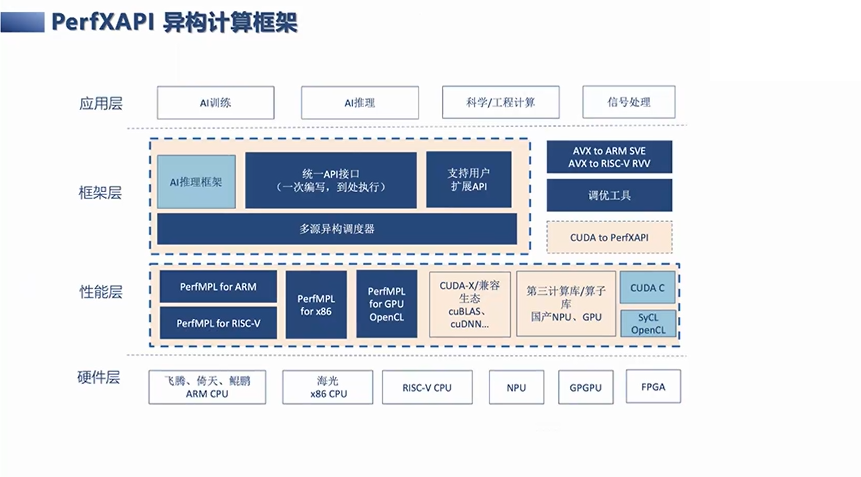
本身PerfXAPI框架这一层,不仅是对库的使用和调用,也有AI推理框架,也有用户自定义的扩展API接口支持,比如用CUDA C或者SYCL、OpenCL来写自定义扩展API。具体的性能层上,有用自己的商业版本的计算库,也有用芯片公司或者其他开源的库等等。
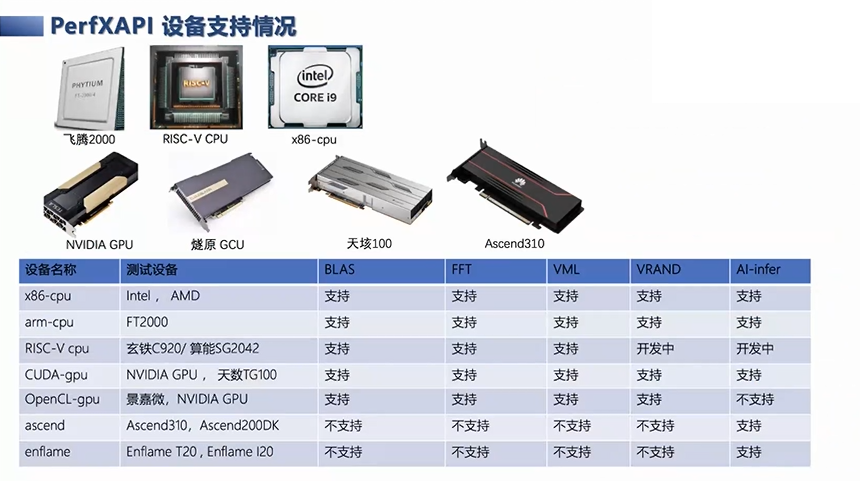
我们目前支持的设备,从服务器角度,包括了x86-cpu、arm-cpu、飞腾CPU、鲲鹏CPU等,以及异构的设备,包括了英伟达的GPU、OpenCL的GPU,还有其他的NPU,像鲲鹏等等,都是我们目前设备支持的。
PerfxLLM架构特点和优势
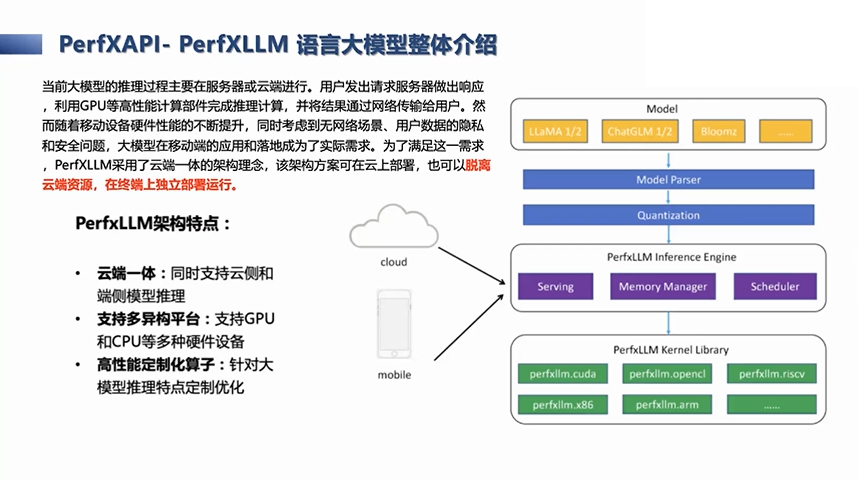
我们还会再进一步,向边缘端方向发展,我们认为这套基础的计算软件栈不仅能用在服务器端,也能用在边缘节点或手持设备上,所以我们实际上就以大语言模型的推理,作为一个案例或Demo。这是我们框架部分的PerfxLLM。我们不只是给云端,也要给边缘侧,这是一个一体化的推理优化,也是支持异构性的,比如手持端的OpenCL的GPU等等,本身后端也会针对库做定制的优化,这是我们在大语言模型的推理上的工作。
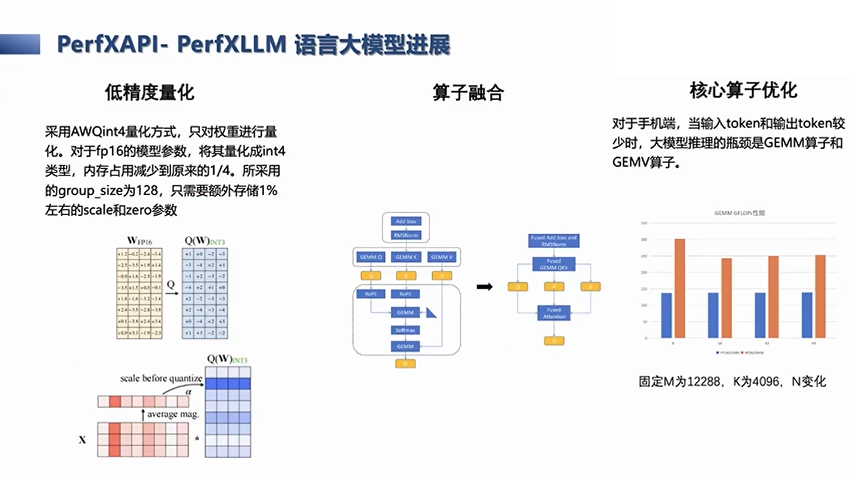
进一步来说,我们目前的推理工作是在手机上进行的,所以它里面比如一些Batch size都是等于一的,所以这里常见的一些优化策略,就是为了降低内存消耗,要做低精度的量化,让模型能在内存受限的场景下运行。其他常见的优化策略,还有算子融合策略,还有针对OpenCL GPU的优化,算子优化的策略等等。这都是我们常见的几种,或者是目前在框架里应用的几种优化方法。
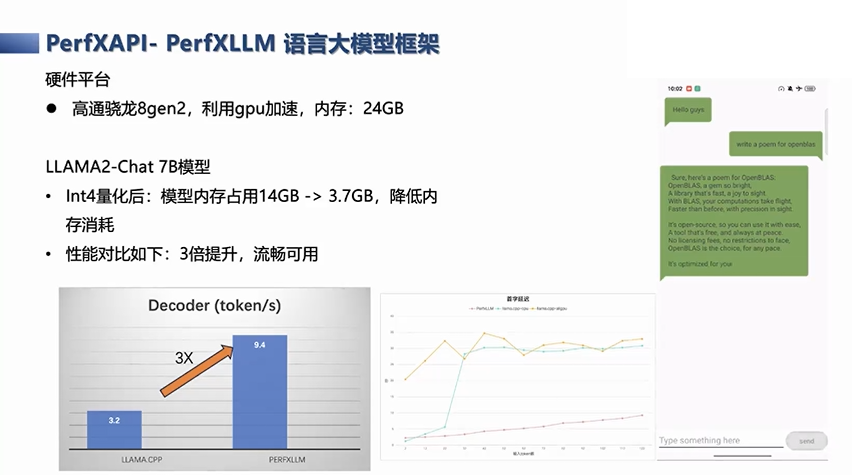
这个演示是我们在推理框架基础上套了一个安卓App展示,部署在了高通骁龙的8gen2的SOC上,本身它这里是使用了GPU的加速,这款手机实际上有24GB的内存,所以在这上面可以看到运行实际上是处在飞行模式,是在本地运行的。这上面的模型是一个LLMMA2-Chat 7B的模型,如果7B模型直接跑fp16精度,它的模型内存的占用量大概是14GB,如果加上系统消耗,需要占用16GB。但是,通过Int4量化之后,内存占用量大概在3.7GB左右。所以即使算上安卓系统的内存开销,在16GB的手机或者更低内存占用的手机,本身是可以运行起来的。
另外,我们还对一些计算速度进行了对比,主要从两个维度来看。一个是每秒平均token输出,刚才展示的就是我们token的输出速度,大概decoder速度达到了九点几,大概10个token。可以看到,这样的速度在终端的显示屏和效果上,已经接近流畅,而且远远超过了开源的LLAMA.CPP的结果。
另一个是首字延迟的问题,我们也有比较明显的优势,大概在一秒多或者不到两秒的时间内,首字就会输出出来。当然,这里还有进一步需要优化的地方,因为随着输入的语句或token数量的增长,首字延迟也会呈上升的趋势,这实际上也说明了我们还有进一步可优化的空间。这是我们目前在端侧的推理加速的工作,未来可能还需要适配更多的嵌入式设备,或者到云端设备做进一步优化,这是我们之后要做的事情。

总结一下,澎峰科技一直在关注计算基础软件,都是希望通过库、框架、异构计算框架构建统一的开源库,降低应用的迁移成本。在异构领域,我们也是通过自己的PerfXAPI实现一次编写,多种异构平台的平滑迁移,满足高性能的指标。我们现在已经支持了国内外主流的异构芯片,很多都是服务器级别的。最近几个月,在大模型推理领域,我们也在尝试往边缘端走,做了第一个在PerfXLLM手机端的推理。
我的报告就到这里,谢谢大家。
Q&A
席友:从厂商的角度来看,推出一个更小的模型,和用你们的方式让手机在端侧上运行,这两种方式有什么本质的差异呢?
张先轶:其实这两个工作是不冲突的,因为我们不涉及模型的减值或做更小的模型的策略,这两种方法是可以互相配合的。一方面是让模型更小,这意味着需要的计算量更少;另一方面是从系统层、infra层上做加速,这两个相乘起来,效果会更好。因为现在很多人都在关注你的速度到底是什么水平,可能大家觉得已经不错了,但当然是速度越快越好。
这里对于速度的追求有三种路径来做:
一种路径是算法,也就是AI模型,在大语言模型上是不是能做更小的模型。我们是以开源的7B为Demo来做的,是不是其他的Nano的或者是微软出的可能是在2B的水平上,比如比LLMMA2 7B更好,这些都会让计算量这部分的性能提升很多。
第二种是我刚才说的工作,从推理框架或者各种量化技术上做优化,这些都属于系统层的软件技术库,这是第二种途径,也是我们做的。
第三种是涉及芯片,像之前针对传统CNN做的,比如NPU或者其他的,当然目前的加速单元IP或者是嵌入式GPU,还是之前的NPU,它们是不是对大语言模型的支持,比如这个工作其实只用了嵌入式GPU,它并没有用到NPU的部分,当然这里面跟细节的各种编程方式有关。
另一方面,也可能是之前的NPU,它设计的时候很多都是针对卷积操作做了优化,但是可以看到大语言模型里其实没有卷积算子,它主要还是一些矩阵乘法或者一些其他的结构,这可能对硬件设计的NPU的架构提出了一些要求,我相信现在很多芯片公司也在这方面做改进和工作。
另一方面,从整体上看,这些大语言模型对带宽的需求是比较高的,它会超过之前的ResNext或者是yolo对带宽的需求,所以这可能也需要在整个系统设计上考虑,就是内存带宽的影响。
席友:如果在端侧运行,可以实现一些什么样的能力呢?
张先轶:我的观点是,跑在端侧的本地模型肯定不可能太大,也就在几B量级的。我觉得这个能力是有限的,实际使用还是端云结合的方式更现实。从我们的性能角度说,我们拿了一个过去的模型,但是要真正实现产品化,估计还是要端云结合去做,这可能是目前我们看到的一个比较好的思路。
席友:端侧异构推理的需求真实吗?感觉会是单卡部署。
张先轶:这个还挺真实的,如果你是在手机端,可能只是单独设备,你的Batch size等于1,模型要小,装得下,这种场景下可以认为是单卡部署,不管是用NPU还是用GPU,或者DSP之类,实际上是一个单设备来做。但是如果是在云端的部署,很多模型就不一定是跑7B的模型,可能会是一个比较大的语言模型,单卡不一定能放得下,或者即便能放下一些卡,也太贵了,大家都用那些卡做训练,你可能就会想如何在一些中低成本的卡上,用单节点多卡的模式把这个问题解决,这是云端的一些需求。
全文完

嘉程资本Next Capital是一家专注科技领域的早期投资基金,作为创新者的第一笔钱,我们极度信仰科技驱动的行业创新,与极具潜力的未来科技领袖共同开启未来。
我们的投资涵盖人工智能、硬科技、数字医疗与健康、科技全球化、生物科技与生命科学、企业服务、云原生、专精特新、机器人等领域。投资案例包括元气森林、熊猫速汇、寻找独角兽、店匠、士泽生物、芯宿科技、未名拾光、橄榄枝健康、硅基仿生等多家创新公司。
嘉程资本旗下的创投服务平台包括「嘉程创业流水席」,「NEXT创新营」、「未来联盟」等产品线,面向不同定位的华人科技创新者,构建了大中华区及北美、欧洲和新加坡等国家地区活跃的华人科技创新生态,超过3000位科技行业企业家与巨头公司高管在嘉程的平台上分享真知灼见和最新趋势。
嘉程资本投资团队来自知名基金和科技领域巨头,在早期投资阶段富有经验,曾主导投资过乐信(NASDAQ:LX)、老虎证券(NASDAQ:TIGR)、团车(NASDAQ:TC)、美柚、牛股王、易快报、PingCAP、彩贝壳、云丁智能等创新公司的天使轮,并创办过国内知名创投服务平台小饭桌。
嘉程资本
握手未来商业领袖
BP 请发送至 BP@jiachengcap.com
微信ID:NextCap2017